I’ve recently been doing some development on a generative city builder. The inspiration for this was watching my son play trashy driving games on an iPad. Some of them take place in very dull cities with poorly generated buildings. My initial idea was that it probably isn’t too hard to build more realistic cities. I had previously been building an orchestration system for Claude agents, but I was getting a bit disenchanted that I was building anything particularly interesting and that the tooling would exist in models etc. Better to build something fun and possibly useful.
If creating a world is cheap, you can invent games that go on the top. In the past, I’ve made games and then struggled when it came time to build more levels and longevity. The core engine was the interesting bit. The rest of it was a chore.
Building the world generator first might be an inversion of that frustrating pipeline. This is perhaps the meta question that we need to be asking ourselves: “which part of the project do I want to be working on? Where will I feel that I will be able to make my mark?”.
For software engineers, we’re having to come to terms with the idea that our contribution is not necessarily the code. That may become a derived product from the intention of the project. It’s this latter that we have to work on and refine in our work.
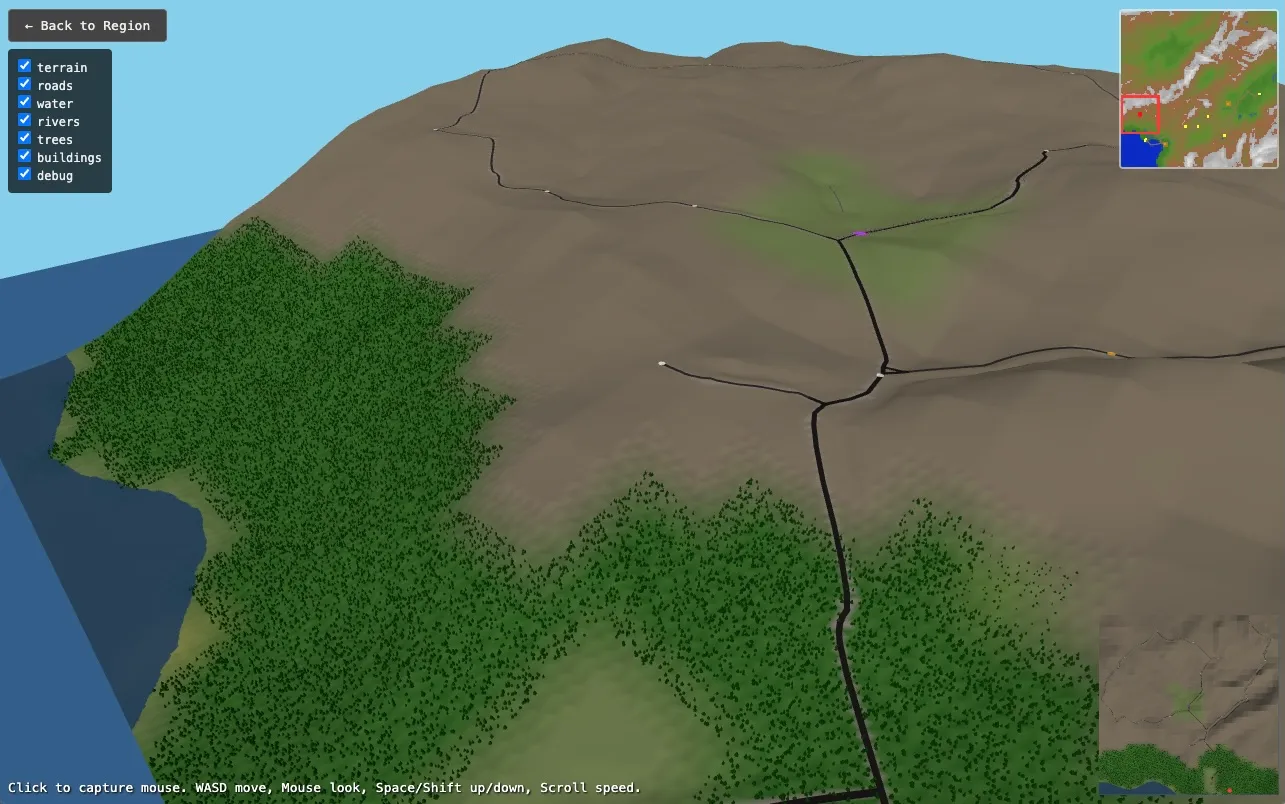
In the first version of the game, I made a city grid of roads that you could drive a car around in. The terrain was gently hilly, and the city blocks were populated with different kinds of buildings based on proximity to center. This worked reasonably well, but looked very “planned” and not like an organic city like London. This is where I embarked on a quest to make something a bit more interesting.
I’m going to take a break from my orchestration project. Everyone’s going to converge on the same ideas anyway. Instead, I’m just going to build fun stuff: https://t.co/MSftn9S4K7 pic.twitter.com/zT91AMoSF2
— Max Williams (@maxthelion) March 4, 2026
The idea was to generate terrain for a city and a realistic arterial network of roads that could be infilled with smaller connecting roads. While thinking about this, I concluded that:
- Cities occur in areas of a map that are suitable for them to flourish
- Arterial roads are connections to other places that have to work their way through the landscape
- Those other network nodes are similarly placed for a favourable position
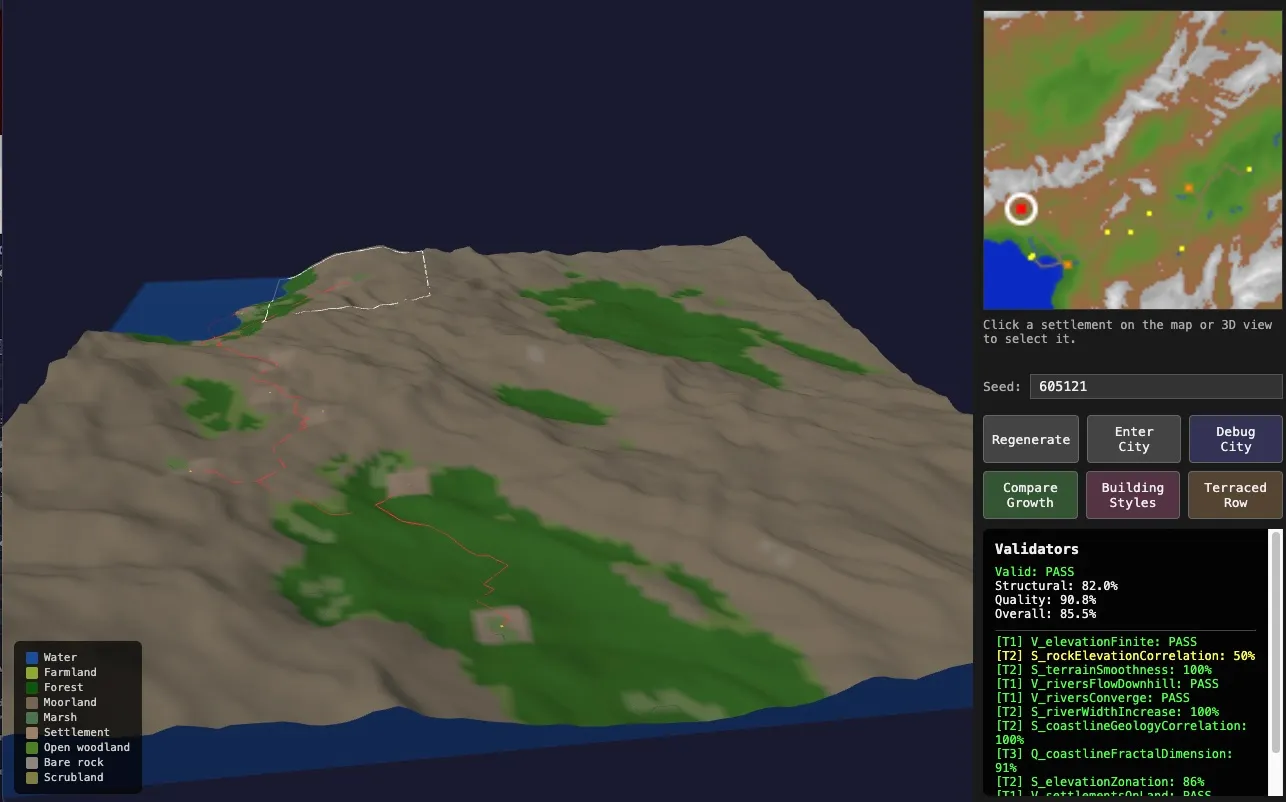
So to generate a realistic city, one really needs to generate a region with topology and pick places that are most suitable. The region should have things like rivers, coastline, population centres and connections between them. When zooming in to a city area, the macro features should be imported, but then refined for greater granularity. The city could then experience a kind of forced growth process to fill it out with developed areas, more connections etc. I also wanted the region to be as realistic as possible, meaning that it should be based on simplified geological processes. It still uses things like Perlin noise, but is very directed. Rivers need to have a certain logic to them.
Combinatorial powerhouses
The idea above sounds kind of cool in principle, but in practise there’s a lot of nuance to it. I first started chatting with Claude about it to try to get some kind of spec together. This is where I had an interesting insight that LLMs are very good at combining existing prior art together in new ways. While I have some knowledge about how geological processes affect a region, or why cities are located where they are, it is incomplete. The LLM is able to cover aspects that I hadn’t thought about.
It created a very good specification that contained a whole pipeline of processes. Each one was informed by ideas that already existed and the whole thing looked very believable. After one-shotting it, and ending up with something that was kind of a mess. I had to think about it more carefully.
Most applications have to be built iteratively
After having the first version end up rather disappointing, I realized that I had to build a composeable system with inputs and outputs. Each one requires tweaking to get to the desired output. If the pipeline is all bleeding together, there are too many permutations lost in the mechanism to reason about. An error at one stage gets multiplied downstream.
Doing this I discovered that I needed to:
- Find ways to visualize experimentation
- Parallelize experimentation
- Focus on the learning, not the artefacts
Visualize with custom interfaces
A fundamental issue with a pipeline like this is that at every stage there are multiple ways of generating an output (and issues!). If these steps are a black box, then it’s very hard to diagnose what is going on. Luckily LLMs are very good at creating completely novel single-use interfaces. Some examples Claude built:
- a simple 3d region viewer to see what terrain was being created and where the cities would be placed.
- a city viewer for all the pipeline steps that renders them as bitmaps side by side (water, elevations, road networks etc)
- building viewers covering different aspects: different features being added to a building, how rows of houses look next to each other, how they sit on hills
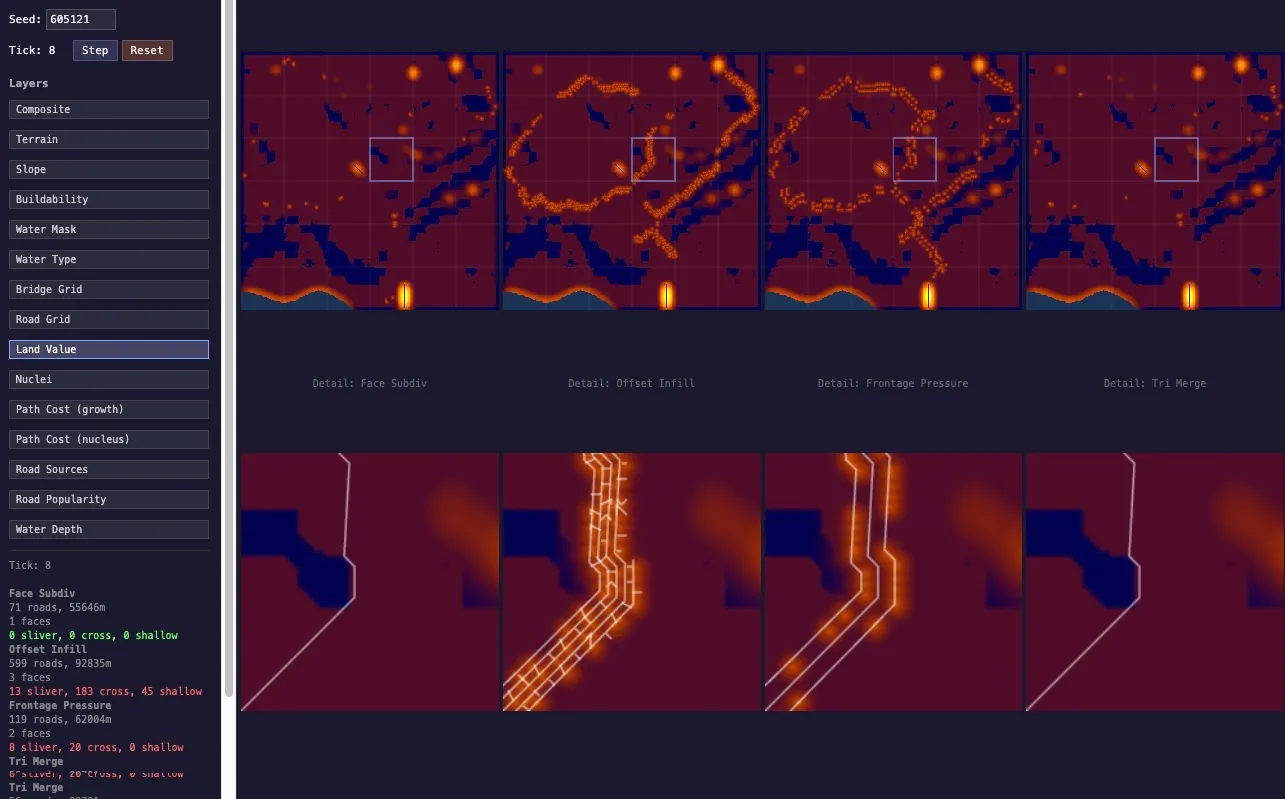
This latter was actually interesting for how badly it initially failed. I asked Claude to do a matrix of different kinds of buildings on 2 axes: plot size and density. I asked for them being all of a similar architectural style, which we had discussed. The results were very poor, even though we’d discussed the approach. The problem, was that these were being built from first principles: the agent was apparently concentrating on building the buildings and the viewer interface and making everything a bit broken.
The fix was to allow the agent to be a composer of sub assemblies. Claude then created a system that started from a box and then added windows, doors, different styles of roof, porches etc. We built a custom viewer for adding all these different things to a house. The important thing was that these operations were composeable. When I then asked Claude to create a few rows of victorian terraced houses, or parisian appartments, it was able to do it very quickly. Again the interface for the building composer was important for understanding what the options should be, but ultimately an LLM can create a combinatorial explosion of options from it.

Parallelize experimentation
As touched on above, one of the goals of the process of building this pipeline is to understand what the design choices are that create different outcomes. In the example of the building generator above, the questions were of the form: “can our building composer create the kinds of buildings we’ve been discussing?”, or “can we build rows of houses on different directions on sloping terrain?”. If these can be answered in isolation then it helps everything else downstream.
In both cases, we could try the different scenarios in a linear fashion “now try it with x”, but that’s kind of tedious. If we get it right, it allows trying matrices of different options that we couldn’t even imagine.
This insight came from a conversation about the different ways that we could do infill of streets off the starting road skeleton. Claude’s response was: “there are a bunch of different options, which would you prefer?”. To which I responded “build them all, create an interface for comparing them side by side”.



Focus on the learning
Ultimately, much of software development is about learning what the best solution to a given problem is. When I tried to one-shot my city generator, I did it based on a fairly detailed plan. But that plan was based on assumptions that turned out to be less than ideal. It also left out many ideas that were only obvious after seeing results.
This leads me to an idea that I’ve been considering a lot recently. Whether it is possible to accumulate enough information about how a system is built such that it can be rebuilt from scratch from that description. This seems to be the ultimate antidote to AI code slop. The problem is that learning about the problem and potential solutions involves building stuff. It involves changing your mind. My experience is that working iteratively leads to layers of new code paths being added on top of stuff that already exists. It requires a lot of diligence about refactoring into better abstractions.
In this project I experimented with the idea of working exploratively to find the correct way of building something. The idea was to update a design spec with the decisions and highlight the important aspects of the system. I then recreated the app from scratch at various points with the updated description.
This had mixed success, but wasn’t a complete disaster. It often cleaned up the system, but sometimes left things out. It has been hard to be super consistent with updating specs when experimenting. It feels like it needs a more systematic approach than I’ve been able to arrive at.
It does remind me of the concept of “spikes” from XP and agile software development. In my remembering of these, they were timeboxed experiments designed to learn more about how projects could be built and to increase certainty about estimates. One of the key parts was that spikes allowed a certain relaxation of the rules about testing and code quality because the learning was the product.
The idea was that the code was actually thrown away at the end of the spike. The learnings were then used to build the thing properly. In practise, I think that it is very psychologically difficult to throw away code that you’ve invested time in, and the code was probably kept more often than not.
It’s interesting to me that some of these ideas may be worth exploring again as the economics of building software changes. It’s cheap to explore and improve learning, it’s also cheap to add complexity and mess to a codebase. I wonder if ultimately the codebase is more of a derived product taken from architectural decisions, functionality, UI, and underlying data model.